


اطلاعات عمومی
ایمونوانفورماتیک چیست؟
ایمونوانفورماتیک
مقدمه
حجم زیادی از داده های مربوط به تحقیقات ایمونولوژی به دلیل تعیین توالی ژنوم انسان و سایر ارگانیسمهای نمونه جمع آوری شده است. در عین حال ، هر روزه حجم عظیمی از داده های بالینی و اپیدمیولوژیک با ادبیات مختلف علمی و سوابق بالینی تولید و ذخیره میشود. این تجمع اطلاعات مانند معدن طلا برای محققانی است که به دنبال مکانیسم عملکرد سیستم ایمنی و بیماریزایی بیماریهای مختلف هستند. بنابراین نیاز به رسیدگی به این منبع اطلاعاتی گسترده ایمونولوژیکی که به سرعت در حال رشد است زمینه ای را ایجاد کرده است که به آن ایمونوانفورماتیک می گویند. ایمونوانفورماتیک یا ایمونولوژی محاسباتی ، رابط بین علوم کامپیوتر و ایمونولوژی تجربی است که نشان دهنده استفاده از روش ها و منابع محاسباتی برای درک اطلاعات ایمنی شناسی است. ایمونوانفورماتیک نه تنها به مدیریت حجم بالا از دادهها کمک میکند ، بلکه نقش بسزایی در تعیین فرضیههای جدید مربوط به پاسخ های ایمنی دارد. استفاده از این سیستم ها با هدف صرفهجویی تا حد ممکن در زمان و هزینه است.
پایگاه داده های ایمونولوژیکی نقش مهمی در انتشار دانش دارند و مستقیماً به درک بهتر ما از مکانیسم های نهفته در سیستم دفاعی بدن انسان کمک می کنند. بدون دادههای مناسب ،امکان ساخت ابزارهای بیوانفورماتیکی موثر که توانایی انجام تفسیرهای معنادار ایمونولوژیک را فراهم کند وجود ندارد. تا ماه می سال 2017 ، 36 پایگاه داده ایمونولوژیکی در مجموعه پایگاه های زیست شناسی مولکولی NAR (NAR Molecular Biology Database Collection) تعریف شد. پایگاه داده های توالی های ایمنی، به صورت تجربی دسترسی به توالی های سلولهای ایمنی را که در پاسخ به عفونت ها و ایمنی ذاتی دخیل هستند ، فراهم می کند. پایگاه داده های اپیتوپ ایمنی مجموعه ای از پایگاه داده های تخصصی هستند که داده های اختصاصی از مولکول های ایمنی() را طبقهبندی و ذخیره می کنند. چنین اطلاعاتی معمولاً برای اطلاع از طراحی واکسن های بر پایه subunit استفاده می شود.
سیستم ایمنی بدن
بدن انسان دارای یک سیستم ایمنی پیچیده در برابر تهدیدات مداوم عوامل بیماری زا محیطی است. هر فرد دارای سیستم ایمنی منحصر به فرد است و به طور متفاوتی به چالشهای ایمنی پاسخ میدهد. سیستم ایمنی ترکیبی از ساختارها و فرایندهای بیولوژیکی داخل بدن است که محافظت از آن در برابر بیماریها را انجام میدهد. اولین مرجع رسمی در تاریخ شروع علم ایمونولوژی به 430 قبل از میلاد بر می گردد.در سال 1798 ، ادوارد جنر (Edward Jenner)برخی ازکارگران شیردوشی را در برابر آبله مصون دانست زیرا قبلاً با آبله گاو (بیماری خفیف) تماس داشتند. پیشرفت بزرگ بعدی در زمینه ایمونولوژی ایجاد ایمنی در برابر وبا بود که توسط لوئیس پاستور انجام شد. وی پس از استفاده از عامل بیماری زای ضعیف شده بر روی حیوانات ، دوز واکسن را به پسر بچه ای تزریق کرد که سگی مبتلا به هاری او را گاز گرفته بود اما نجات یافته بود. پاستور نمی توانست مکانیسم و علت این امر را توضیح دهد.در سال 1890 ، آزمایشات امیل فون بهرینگ(Emil Von Behring) و شیباسابوروکیتاساتو (ShibasaburoKitasato) منجر به درک مکانیسم سیستم ایمنی شد.
اولین خط دفاعی توسط سیستم ایمنی ذاتی هدایت می شود ، که یک ایمنی عمومی غیر اختصاصی در برابر عفونت است که به سرعت در هنگام عفونت این پاسخ ایجاد می شود . سلولهای سیستم ایمنی ذاتی عوامل بیماری زا را بطور کلی تشخیص داده و به آنها پاسخ می دهند ، زیرا انواع مختلفی از گیرنده ها برای تشخیص ویژگیهای مشترک عوامل بیماری زا وجود دارد. بنابراین ، اثرات مصونیت بر میزبان کوتاه مدت است. در مقابل ، سیستم ایمنی اکتسابی بسیار تخصصیتر است و میتواند در صورت فرار عوامل بیماری زا از ایمنی ذاتی ، عفونت را از بین ببرد. سیستم ایمنی اکتسابی ، متشکل از سلول های B و سلول های T میباشد، برای تشخیص عفونت های خاص شکل گرفته و منجر به ایمنی طولانی مدت میشود. لنفوسیت های عملکرد سیستم ایمنی اکتسابی برمبنای شناسایی یک ساختار شیمیایی ویژه که توسط نوعی گیرنده خاص میباشد که منجر به ایجاد تنوع زیادی از مجموعه وسیعی از ایمونوگلوبولین ها و گیرنده های سلول T می شود.
پایگاههای دادهای مهم در ایمونوانفورماتیک
در ادامه، چند پایگاه داده اصلی را که برای تحقیقات ایمونوانفورماتیک موجود هستند ، معرفی می کنیم. از جمله پایگاه های داده جامع مانند IEDB که داده های اپیتوپ و اطلاعات ساختار را ارائه می دهد وپایگاه های داده تخصصی در ژن ها و ….. .
IEDB
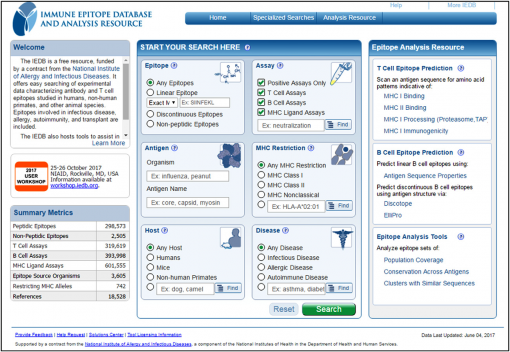
پایگاه داده و منبع تجزیه و تحلیل اپیتوپهای ایمنی (IEDB ؛ mmune Epitope Database and Analysis Resource) یک منبع اصلی ایمونوفورماتیک است ، با مجموعه گسترده ای از اپیتوپ های سلول B و T که به طور تجربی در انسان ها ، نخستی های غیر انسانی ، موش ها و سایر گونه ها مشخص شده است. با حمایت مالی موسسه ملی آلرژی و بیماری های عفونی (NIAID)، این پایگاه داده در سال 2004 در موسسه آلرژی و ایمونولوژی لا ژولا(La Jolla Institute) با هدف کمک به محققان در پیشرفت تشخیصهای جدید ، درمان و طراحی واکسن توسعه یافت.
پایگاه داده حاوی اطلاعاتی در مورد اپیتوپ های پپتیدی و غیر پپتیدی ، و همچنین سنجش لیگاند سلول T ، سلول B و MHC است که از ادبیات معتبر و داده های ارائه شده توسط محققان تهیه و گردآوری شده است. هر سری اطلاعاتی ذخیره شده شامل توالی ، ارگانیسم منبع ، آنتی ژن منبع و منابع مرتبط با اطلاعات مذکور است که شامل نویسنده ، عنوان و چکیده است. تا ژوئن 2017 ، IEDB شامل بیش از 298،000 اپیتوپ پپتیدیک و 2500 اپیتوپ غیرپپتیدی از بیش از 3600 موجود زنده است که بر اساس تقریبا 319،000 سنجش سلول T ، 393،000 سنجش سلول B و 601،000 سنجش لیگاند MHC انجام شده است.که این بیش از 99 % از تمام اطلاعات اپی توپ پپتیدی را که در دسترس عموم است ، شامل میشود.
IMGT
سیستم های اطلاعاتی بین المللی (IMGTs ؛ international ImMunoGeneTics information systems) یک منبع اطلاعاتی یکپارچه برای ایمونوگلوبولین ها ، سازگاری های بافتی و گیرنده های سلول T در انسان و سایر مهره داران است. IMGT که در سال 1989 توسط Marie-Paule Lanfranc ایجاد شد ، ژن ها و پروتئین های متنوع و پیچیده ایمونوگلوبولین و گیرنده های سلول T و همچنین پلی مورفیسم پروتئین های سازگاری با بافت را طبقهبندی می کند. در کل شامل هفت پایگاه داده است:
- IMGT / LIGM-DB : یک پایگاه داده جامع از توالی های نوکلئوتیدی از ایمونوگلوبولین و گیرنده های سلول T از انسان و دیگر مهره داران است. هر تولی در پایگاه داده شامل اطلاعات مربوط به شناسایی توالی ، طبقه بندی ژن و آلل ، توصیف موتیف های اساسی و اختصاصی ، شماره گذاری کدون و اسید آمینه است. تا ژوئن 2017 ، بیش از 178،000 توالی گیرنده ایمونوگلوبولین و سلول T از 351 گونه در این پایگاه وارد شده است

- شکل 1 صفحه اصلی IEDB که در آن کاربران می توانند با انجام پرس و جوهایی بر اساس اپی توپ ها ، سنجش ها ، آنتی ژن ها ، نوع MHC ، میزبان و بیماری ها ، دسترسی به داده ها را آغاز کنند. IEDB موجود در http: //www.iedb.org.
- IMGT / MH-DB در توالیهای پیچیده سازگاری بافتی اصلی انسان تخصص دارد. پایگاه دادهای که به عنوان پایگاه داده مخصوص توالی آللی ژن های HLA ایجاد شده است ، همچنین شامل توالی های رسمی مشخص شده توسط کمیته نامگذاری سازمان بهداشت جهانی برای فاکتورهای سیستم HLA می باشد. تا ژوئن 2017 ، 12351 آلل HLA کلاس 1 ، 4404 آلل HLA کلاس II و 178 آلل غیر HLA در پایگاه داده وجود دارد.
- IMGT / PRIMER-DB پایگاه داده الیگو نوکلئوتیدها (پرایمر) ایمونوگلوبولین و گیرنده سلول T است. پرایمرها را می توان به عنوان متغیر آنتی بادی تک زنجیره ای single chain Fragment variable (scFy) ، طراحی کتابخانه ترکیبی ، فناوری ریزآرایه و نمایش فاژ استفاده کرد. پایگاه داده شامل 1864 پرایمر از 11 گونه است.
- IMGT / CLL-DB یک پایگاه داده تخصصی در توالی ایمونوگلوبولین اولیه است که با داده های بالینی و بیولوژیکی بیماران مبتلا به لوسمی لنفوسیتی مزمن (CLL) مرتبط است.
- IMGT / GENE-DB یک پایگاه داده جامع برای ژنهای کدکننده گیرنده گلوبولین ایمنی و سلول T از انسان ، موش ، موش و خرگوش است. پایگاه داده مرجع بین المللی برای نامگذاری ژن ایمونوگلوبولین و گیرنده سلول T است که داده های ژنی مربوط به ژنوم ، پلی مورفیسم آللی ، بیان ژن ، پروتئین و ساختارها را دارا میباشد. تا ژوئن 2017 ، پایگاه داده شامل 4147 ژن و 5858 آلل از 24 گونه است
- IMGT / 3D structure-DB منبعی برای اطلاعات ساختاری ایمونوگلوبولین ، گیرنده سلول T ، MHC و پروتئین های مربوط به سیستم ایمنی است. با 4766 مدرک اطلاعاتی در حال حاضر ، هر داده ذخیره شده،اطلاعاتی در مورد توالی ، ساختارهای 3بعدی و 2بعدی ارائه می دهد.
- IMGT / mAB-DB یک پایگاه داده آنتی بادی های مونوکلونال است که منابع ایمونوگلوبولین ها یا آنتی بادی های مونوکلونال با علائم بالینی و پروتئین های تلفیقی را برای کاربردهای ایمنی ارائه می دهد. تا ژوئن 2017 ، پایگاه داده شامل 722 پرونده شده است.

SYPPEITHI
یکی از اولین پایگاه داده های عمومی موجود برای لیگاندهای MHC و موتیف های پپتیدی SYFPEITHI است. پایگاه داده ای از توالی های پپتیدی شناخته شده است که به مولکولهای MHC کلاس I و II متصل شده اند. این پایگاه در سال 1999 توسط گروه هانس-گئورگ رزامی (Hans-Georg Rammensee’s group)در انستیتوی زیست شناسی سلولی ، دانشگاه توبینگن(University of Tübingen) پایهگذاری شد. این پایگاه شامل بیش از 7000 لیگاند MHC ، موتیف و اپی توپ های سلول T میباشد، پایگاه داده به منظور تسهیل جستجوی پپتیدها و کمک به پیش بینی اپی توپ های سلول T است. هر داده ذخیره شده ، اطلاعاتی در مورد منبع و مرجع ارائه می دهد.
AntiJen
AntiJen مجموعه بزرگی از داده های اتصال کمی است. پایگاه داده ای که توسط گروه دارن فلاور(Darren Flower’s group) در موسسه ادوارد جنر(Edward Jenner Institute) برای تحقیقات واکسن پایهگذاری شده است ، با هدف بهبود واکسینولوژی محاسباتی برای ساخت ابزارهایی برای پیش بینی دقیق اپی توپ ها توسعه یافته است. این پایگاه داده شامل سینتیک و لیگاندهای مولکول MHC ، اپی توپ های سلول T ، پپتیدهای تراغشایی (Transmembrane Peptide) انتفال دهنده و اپی توپ های سلول B ، کمپلکسهای پروتئینی و برهم کنشهای پروتئین – پروتئین و همچنین کتابخانه پپتیدی داده ها ، ضریب انتشار است. با بیش از 24000 مدخل بر اساس داده های تجربی تعیین شده ، AntiJen یکی از بزرگترین پایگاه های اطلاعاتی اپیتوپ های ایمنی موجود است.
مترجم: آتوسا بهنام راد
مطالعه صدها مطلب علمی در حوزه بیولوژی
آرشیو جدیدترین خبرهای روز دنیای بیولوژی