


دستهبندی نشده
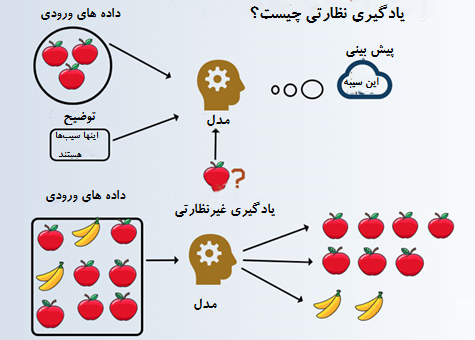
یادگیری ماشین نظارتی چیست؟
مقدمهای بر یادگیری ماشین نظارتی
یادگیری ماشین نظارتی دستهای از الگوریتمهای یادگیری ماشینی است که بر اساس مجموعه دادههای برچسب گذاری شده میباشد. تجزیه و تحلیل پیش بینی از طریق این دسته از الگوریتمها به دست میآید که در نتیجه الگوریتمی که به عنوان متغیر وابسته شناخته میشود به مقدار متغیرهای داده مستقل بستگی دارد. بر اساس مجموعه داده آموزشی است و از طریق تکرارها بهبود مییابد. عمدتاً دو دسته از یادگیری نظارتی وجود دارد، مانند رگرسیون و طبقه بندی. در چندین سناریو دنیای واقعی، مانند پیشبینی بررسیهای فروش برای سه ماهه آینده در تجارت برای یک محصول خاص برای یک سازمان خردهفروشی، پیادهسازی میشود.
کار بر روی یادگیری ماشین نظارتی
بیایید یادگیری ماشینی نظارتی را با کمک یک مثال درک کنیم. فرض کنید یک سبد میوه داریم که پر از گونههای مختلف میوه است. وظیفه ما این است که میوهها را به صورت مشخصی دستهبندی کنیم.
ما چهار نوع میوه را در نظر گرفتهایم: سیب، موز، انگور و پرتقال.
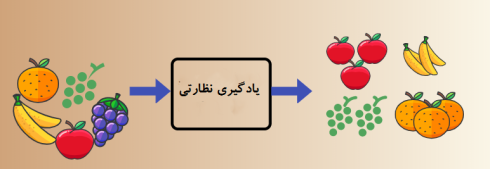
اکنون میخواهیم به برخی از ویژگیهای منحصر به فرد این میوهها که آنها را منحصر به فرد میکند اشاره کنیم.
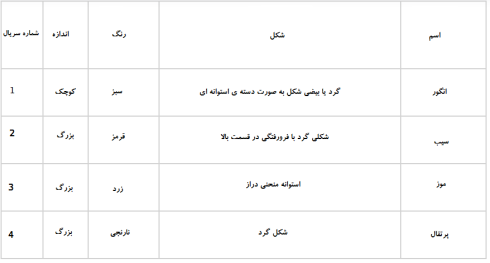
حالا فرض کنیم که شما یک میوه را از سبد میوه برداشتهاید، به ویژگیهای آن نگاه کردهاید، مثلاً شکل، اندازه و رنگ آن، و سپس میگویید که رنگ این میوه قرمز است، از نظر اندازه اگر بزرگ باشد، گرد و فرورفتگی در قسمت بالا داشته باشد نتیجه میگیرید که آن یک سیب است.
- به همین ترتیب، شما همین کار را برای سایر میوههای باقی مانده نیز انجام میدهید.
- سمت راستترین ستون (“نام میوه”) به عنوان متغیر پاسخ شناخته میشود.
- اینگونه است که ما یک مدل یادگیری نظارتی را برنامه نویسی میکنیم. اکنون، برای هر فردی که تازه وارد است (مثلاً یک ربات یا یک بیگانه) با ویژگیهای داده شده، بسیار آسان خواهد بود که به راحتی همان نوع میوهها را با هم گروهبندی کند.
انواع الگوریتم یادگیری ماشین نظارتی
بیایید انواع مختلف الگوریتمهای یادگیری ماشینی را ببینیم:
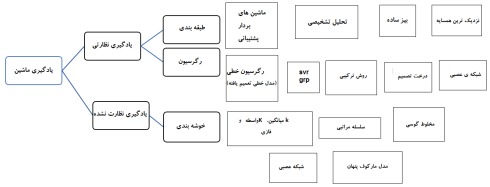
رگرسیون
رگرسیون برای پیشبینی خروجی یک مقدار با استفاده از مجموعه دادههای آموزشی استفاده میشود. مقدار خروجی همیشه متغیر وابسته نامیده میشود، در حالی که ورودیها متغیر مستقل هستند.
ما انواع مختلفی از رگرسیون را در یادگیری نظارتی داریم.
مثلا:
- رگرسیون خطی: در اینجا، ما فقط یک متغیر مستقل داریم که برای پیشبینی خروجی استفاده میشود، یعنی متغیر وابسته.
- رگرسیون چندگانه: در اینجا، ما بیش از یک متغیر مستقل داریم که برای پیشبینی خروجی استفاده میشود، یعنی متغیر وابسته.
- رگرسیون چند جملهای: در اینجا نمودار بین متغیرهای وابسته و مستقل از تابع چند جملهای پیروی میکند. برای مثال در ابتدا حافظه با افزایش سن افزایش مییابد، سپس در سن خاصی به آستانهای میرسد و با پیری شروع به کاهش میکند.
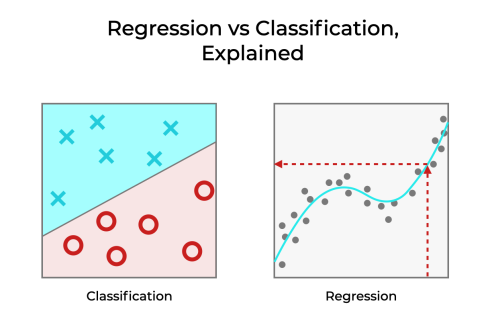
طبقه بندی
طبقه بندی الگوریتمهای یادگیری نظارتی برای گروه بندی اشیاء مشابه در طبقههای منحصر به فرد استفاده میشود.
طبقه بندی باینری (binary): اگر الگوریتم سعی کند دو گروه مجزا از دستهها را گروه بندی کند، آن را طبقه بندی باینری مینامند.
طبقه بندی چند دستهای : اگر الگوریتم بخواهد اشیاء را در بیش از دو گروه، گروه بندی کند، طبقه بندی چند دستهای نامیده میشود.
توانایی: الگوریتمهای طبقه بندی معمولاً عملکرد بسیار خوبی دارند.
معایب: آمادهی قرار دادن تعداد بیش از اندازه متغیر مستقل میباشد و ممکن است ظرفیتش نا محدود باشد. به عنوان مثال: طبقه بندی کننده اسپم ایمیل.
رگرسیون/طبقهبندی لجستیک: وقتی متغیر Y یک دستهبندی باینری است (یعنی 0 یا 1)، ما از رگرسیون لجستیک برای پیشبینی استفاده میکنیم. به عنوان مثال پیشبینی اینکه آیا اشتباهی در تراکنش کارت اعتباری رخ داده است یا خیر.
طبقه بندی کنندههای ساده بیز: طبقه بندی کننده ساده بیز بر اساس قضیه بیز است. این الگوریتم معمولاً زمانی که ابعاد ورودیها زیاد باشد، مناسبتر است. از نمودارهای غیر چرخهای تشکیل شده است که دارای گرههای یک والد و تعداد زیادی فرزند هستند. گرههای فرزند مستقل از یکدیگر هستند.
درخت تصمیم: درخت تصمیم ساختاری شبیه نمودار درختی است که از یک گره داخلی (تست ویژگی)، شاخهای که نتیجه آزمون را نشان میدهد و گرههای برگ، که توزیع دستهها را نشان میدهد، تشکیل شده است. گره ریشه، بالاترین گره است. این یک تکنیک بسیار پرکاربرد است که برای طبقه بندی استفاده میشود.
ماشین بردار پشتیبان: یک ماشین بردار پشتیبان یا SVM که کار طبقه بندی را با یافتن هایپرپلن انجام میدهد، که باید حاشیه بین دو دسته را به حداکثر برساند. این ماشینهای SVM به توابع هسته متصل هستند. زمینههایی که در آن SVM ها به طور گسترده مورد استفاده قرار میگیرند، بیومتریک، تشخیص الگو و غیره هستند.
مزایا
در زیر برخی از مزایای مدلهای یادگیری ماشین نظارتی آورده شده است:
تجربیات کاربر میتواند به عملکرد مدلها را بهبود ببخشد.
با استفاده از تجربه قبلی خروجی تولید میکند و همچنین به شما امکان میدهد دادهها را جمع آوری کنید.
الگوریتمهای یادگیری ماشین نظارتی را میتوان برای پیاده سازی تعدادی از مسائل دنیای واقعی استفاده کرد.
معایب
در زیر معایب ذکر شده است:
- اگر مجموعه داده بزرگ باشد، تلاش برای آموزش مدلهای یادگیری ماشین نظارتی ممکن است زمان زیادی ببرد.
- طبقه بندی کلان دادهها گاهی اوقات چالش بزرگتری را ایجاد میکند.
- ممکن است فرد مجبور باشد با مشکلات زیادی دست و پنجه نرم کند.
- اگر میخواهیم مدل در حین آموزش طبقهبندیکننده عملکرد خوبی داشته باشد، به نمونههای خوب زیادی نیاز داریم.
اقدامات خوب در ساختن مدلهای یادگیری
اقدامات خوب در هنگام ساخت مدل ماشین موارد زیر است:
- قبل از ساخت هر مدل یادگیری ماشین خوب، فرآیند پیش پردازش دادهها باید انجام شود.
- فرد باید الگوریتمی را انتخاب کند که برای یک مسئله معین مناسبترین باشد.
- ما باید تصمیم بگیریم که چه نوع دادهای برای مجموعه آموزشی استفاده شود.
- نیاز به تصمیم گیری در مورد ساختار الگوریتم و تابع دارد.
دوره مهارت آموزی هوش مصنوعی: ماشین لرنینگ برای بیولوژیست ها