


دستهبندی نشده
دیتا ZFS

مقدمه ای بر مجموعه داده ZFS
مجموعه داده ایجاد شده توسط Sun Microsystems که به عنوان یک سیستم فایل یا volume manager عمل میکند که در آن دادهها را میتوان برای قرار دادن و ذخیره سازی در سیستمهای محاسباتی کنترل و مدیریت کرد، مجموعه داده ZFS نامیده میشود. سیستم فایل زتابایت (zettabyte) به یکپارچگی دادهها و مقیاسپذیری کمک میکند که در آن تکثیر دادهها به راحتی انجام میشود.
این فایل، یک سیستم 128 بیتی است که در آن 256 کوادریلیون زتابایت را میتوان به راحتی مقیاسبندی کرد. همه دیسکها و فضای ذخیره سازی در یک موجودیت واحد مدیریت میشوند و در صورت نیاز به ظرفیت اضافی، درایوهای بیشتری را میتوان به راحتی اضافه کرد. حداکثر اندازه فایل در جایی پشتیبانی میشود که در آن دو نسخه از ابرداده در هنگام کپی کردن دادهها در دیسک ذخیره میشود.
مجموعه داده ZFS چیست؟
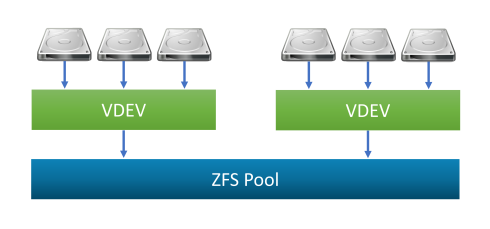
- مجموعه داده ZFS، یک filesystem در داخل سیستم فایل استاندارد است که در آن namespace نصب شدهاست و مانند هر filesystem دیگری برای ذخیره سازی رفتار میکند و به عنوان یک مخزن برای تمام ابردادههای آن عمل میکند. اکثر توزیعهای لینوکس (Linux) از ZFS از طریق ZFS-FUSE استفاده میکنند و مدیر حجم اصلی(logical volume control) سیستم است.
- دستگاهها بهعنوان یک مخزن ذخیرهسازی مدیریت میشوند که در آن فایلها قرار میگیرند و این به ذخیرهگاه داده برای سیستمهای فایلی تبدیل میشود که در آینده ایجاد میشوند. در آن فضای ذخیره سازی مجازی وجود ندارد و تمام ویژگیهای فضای ذخیره سازی مانند افزونگی دادهها، طراحی دستگاه و حذف دادهها در فضای ذخیره سازی توضیح داده شده است.
- ZFS یکی از بهترین filesystem های امروزه با امنیت دادهها و ظرفیت ذخیره سازی در مقیاس بزرگ در filesystems است. پیچیدگیهای متعددی در filesystems وجود دارد، اما امنیت ارائه شده برای دادهها با هیچ filesystem دیگری قابل مقایسه نیست و میتوان از آن در ترکیب با RAID استفاده کرد. همچنین، تمام خدمات را به صورت رایگان ارائه میدهد و باعث میشود کاربران حجم عظیمی از دادهها را ذخیره کنند.
![]()
چگونه میتوانیم از آن استفاده کنیم؟
- یک سرور واحد برای اجرای ZFS استفاده میشود که در آن هر مقدار داده را میتوان به راحتی مدیریت کرد. در صورت نیاز، میتوانیم درایوهای بیشتری را به فضا اضافه کنیم و ذخیره سازی دادهها را حفظ کنیم. در حالی که ابرداده در دیسک ذخیره سازی کپی میشود، ابرداده دارای بخشهای دیسک برای ذخیره دادهها، به اندازهای است که باید ذخیره شوند و یک نقطه بازرسی برای بررسی ارقام باینری موجود در دادهها، وجود دارد. هنگامی که کاربر درخواست دسترسی به دادههای خاص را با مقایسه بیتهای داده موجود در سیستم ذخیره سازی میکند، از این نقطه بازرسی برای تأیید دادهها استفاده میشود.
- اگر دادههای آسیبدیده وجود داشته باشد و اگر مخزن ذخیرهسازی در جای دیگری کپی شده باشد، میتوانیم دادهها را از درایو ذخیرهسازی دیگری بازیابی کنیم و دادههای آسیبدیده را اصلاح کنیم. ZFS سیستم کپی در نوشتن (copy on write system) نامیده میشود و پس از کپی کردن همان دادهها را بازنویسی نمیکند. یک نسخه جدید ذخیره میشود و ابرداده برای همان دادهها با تمام نکات مربوطه و جزئیات نسخه قدیمی به روز میشود.
- مقدار داده قبلی پیش از مقابله بررسی میشود، جایی که خواندن، تغییر و نوشتن برای همه دادههایی که در درایوهای ذخیرهسازی کپی میشوند، دنبال میشوند. محیطهای سرور مجازی و سیستمهای فایل شبکه، گزینههای رایج استقرار سیستمهای فایل ZFS هستند.
بهترین شیوههای فضای دخیره سازی ZFS
- هنگام گرفتن snapshot از ZFS، مطمئن شوید که آنها را برای مراجعات بعدی به حافظه خارجی ارسال کنید. برای این کار میتوان از ارسال و دریافت ZFS استفاده کرد. اسنپ شاتها روشی آسان برای مدیریت نسخههای فایلها هستند و از این رو بهتر است از zfs-auto-snapshot-script در دستگاه استفاده کنید. همچنین، بهتر است از فشردهسازی استفاده کنید، زیرا دادههای ذخیره شده در یک فرمت فشرده خواهد بود که بر روی CPU یا هیچ حافظهای تأثیر نمیگذارد. در صورتی که رم در سیستم موجود باشد، میتوان از Duduplication پیروی کرد زیرا خود deduplication بدون ذخیره سازی RAM باعث پول هنگفتی میشود. بهتر است مجموعه دادههایی برای /home/، /var/cache/ یا /var/log/ ایجاد کنید تا اینکه از آن در سیستمهای ریشه GNU/Linux استفاده کنید.
- ZFS NFS به خوبی نسبت به سیستمهای NFS بومی کار میکند که به اطمینان از اینکه مجموعه دادهها به درستی نصب شدهاند و در جای خود قرار دارند، کمک میکند تا دادهها در زمان فوری دریافت شوند. از NFS Kernel exports به جای ZFS NFS استفاده نکنید زیرا اولی پیچیده است و نگهداری آن در سیستم دشوار است. هنگام نصب مجموعه دادهها در سیستم، بهتر است برای مجموعه دادهها سهمیه بندی شود تا بتوان از مجموعه دادههای تودرتو در ظرفیت ذخیره سازی استفاده کرد.
- هنگام ارسال اسنپشاتها به حافظه خارجی، بهتر است از آن با جریانهای افزایشی استفاده کنید. از این رو، کد مورد استفاده برای صرفه جویی در زمان zfs send-i است. ویژگیهای مجموعه داده را میتوان با استفاده از ارسال ZFS به جای rsync ذخیره کرد و زمان خرابی را میتوان با استفاده از تخریب ZFS کاهش داد.
ایجاد مجموعه دادههای ZFS
- برای نصب ZFS به سرور اوبونتو (Ubuntu) نیاز است. همه اجزا در یک بسته اوبونتو مدیریت میشوند و بنابراین دستور را اجرا کنید.
sudo apt install zfsutils-linux
- هنگامی که دستور اجرا شد، برای بررسی اینکه آیا به درستی نصب شده است یا خیر، عبارت ZFS را اجرا کنید که مکان package ZFS را به ما نشان میدهد. اکنون ZFS را در سیستم نصب کردهایم و لازم است یک storage pool نیز ایجاد کنیم.
- در ابتدا، ما باید درایوهایی را که در آن قصد داریم مخزن ذخیره سازی را نگهداری کنیم، بررسی کنیم. این را میتوان با sudo fdisk -l بررسی کرد. نام درایوها باید برای مراجعات بعدی یادداشت شود. ما میتوانیم مخزنهای striped و مخزنهای آینهای(mirrored) ایجاد کنیم. مخزنهای striped آنهایی هستند که دادهها در همه درایوها به صورت نواری ذخیره میشوند در حالی که مخزنهای آینهای آنهایی هستند که دادهها به طور جداگانه ذخیره میشوند. مخزنهای striped عملکرد بهتری دارند و می توان با sudo zpool برای ایجاد new-pool /dev/mag /dev/ger که dev/mag و dev/ger نام دو درایو هستند ایجاد کرد.
- مخزنهای آینهای با استفاده از sudo zpool ایجاد میشوند.
Create new-pool mirror /dev/sdb /dev/sdc
- اکنون، هر دو مخزن در اوبونتو ظاهر میشوند و ما میتوانیم بر اساس راحتی خود از هر کدام استفاده کنیم. وضعیت مخزنها را میتوان با وضعیت sudo zpool بررسی کرد. در یک مخزن striped، در صورت از کار افتادن درایو، تمام دادهها از بین میروند. بنابراین کاربران بیشتر مخزن آینهای را ترجیح میدهند.
نتیجه
چندین ویژگی در ZFS موجود است که آن را برای کاربران جدید پیچیده میکند. گاهی اوقات به قدرت پردازش اضافی نیاز است و از این رو مدیریت آن توسط کاربران دشوار است. همچنین، اجرا بر روی یک سرور واحد، ظرفیت آن را به پردازش موازی و در نتیجه سیستمهای فایل موازی در چندین سرور محدود میکند.
مترجم: حنانه بریمانی
همچنین اخبار های علمی را بخوانید: